TwitInfo: Aggregating and Visualizing Microblogs for Event Exploration
Authors - Adam Marcus, Michael S. Bernstein, Osama Badar, David R. Karger, Samuel Madden, and Robert C. Miller
Authors Bios - Adam Marcus is a graduate student at MIT and researches with the Artificial Intelligence Lab.
Michael S. Bernstein is a graduate student at MIT with emphasis in human computer interaction.
Osama Badar is a student at MIT and also researchers with the Artificial Intelligence Lab.
David R. Karger is a professor at MIT and has a PhD from Stanford University.
Samuel Madden is an Associate Professor in the EECS department at MIT.
Robert C. Miller is an associate professor at MIT and leads the User Interface Design Group there.
Venue - This paper was presented at the CHI '11 Proceedings of the 2011 annual conference on Human factors in computing systems.
Summary
Hypothesis - In this paper, researchers discuss information gathering about events using twitter and why its current implementation can lead to unbalanced and confusing tweets being displayed. The hypothesis is that the researchers can build a system that organizes and displays information from twitter in a much more coherent and easily understood manner that people can use to understand events quicker than ever.
Content - The TwitInfo System consists of:
- Creating an Event - Users enter in keywords (like Soccer and team names like Manchester) and label the event in human readable form(Soccer: Manchester)
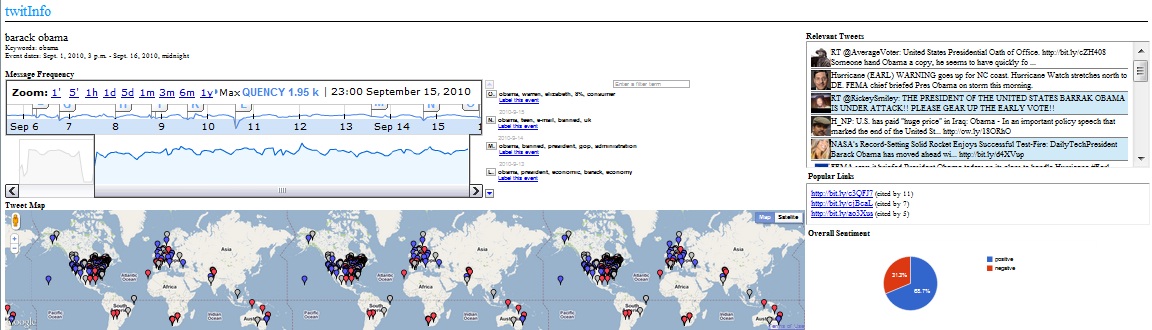
- Timeline and Tweets - The timeline element displays a graph showing the popularity of the keywords entered in and detects peaks which are then marked as events which users can click on which singles out relevant tweets made during that time
- Metadata - Displays overall sentiment (positive or negative) towards the subject matter, shows a map of where tweets are coming from, and gives popular links cited in the tweets
- Creating Subevents and Realtime Updating - Users can create subevents by selecting an event on the timeline and labeling it separately and the system updates as often as twitter does allowing users to always have up to date infromation.
- Event Detection - Keeps track of a mean twitter rate and when the rate is significantly higher than the mean, an event is created
- Dealing with Noise - Keywords that have higher volume than other keywords in the same event are dampened by comparing each keyword with its global popularity and acting accordingly
- Relevancy Identification - Relevant tweets are determined by matching keywords and looking at how many times it has been retweeted
- Determining Sentiment - The probability that a tweet is positive and negative is calculated and if a significant difference is present then it is added to whatever sentiment it is more like
Methods - 1) The researchers first evaluate the validity of their event detection algorithms by examining on their own major soccer and earthquake events of interest without looking at twitter. They will compare these findings with what TwitInfo returns for the two subjects.
2) 12 people were selected for a user study and evaluation of TwitInfo's interface. The participants were asked to look for specific data first such as single events and comparing them. They were then asked to gather information about a topic for 5 minutes and present their findings. The final thing required of the participants was to have an interview with the researchers to discuss the system as a whole.
Results - 1) The researchers found that the system was quite accurate but reported many false positives. They also found that interest is a significant factor in finding information meaning an event that happens in a minor area or an undeveloped area is more likely to go unnoticed in TwitInfo.
2) The researchers found that most people were able to give very insightful reports on current events even with little to no prior knowledge of the events being studied. Common usage of the system found that many people skimmed the event summaries to get an overview of what happened when. The timeline was found to be the most useful part of the interface for most participants. Users also reported that the map would have been more interesting if volume was reflected in the display so as to show where events had the greatest impact.
Conclusion - The researchers conclude by stating that Twitter is quickly becoming a news reporting site for many people so something like TwitInfo could be very useful to them in getting an overview of information quickly.
Discussion
I think the researchers achieved their goal of developing a system that helps people understand events quickly through aggregated tweet analysis. I found the interface particularly interesting and quick acting allowing for overviews or more in depth reporting if desired. I think this system will inspire sites in the future to develop and eventually become dedicated news sources themselves much like Wikipedia has become a leading source for encyclopedic knowledge even though it is entirely user generated.







